Types of Cloud Servers
Choosing the right cloud server type is crucial for optimizing performance, scalability, and cost-effectiveness. Understanding the differences between the available options is key to making an informed decision that aligns with your specific application requirements and budget. This section will explore the main types of cloud servers, highlighting their strengths and weaknesses.
Several types of cloud servers cater to diverse needs, each offering a unique balance of control, scalability, and cost. The choice depends on factors such as application complexity, required resources, and budget constraints. Careful consideration of these factors is essential for optimal performance and cost efficiency.
Comparison of Cloud Server Types
The following table provides a comparison of three primary cloud server types: Virtual Machines (VMs), Dedicated Servers, and Cloud Containers. It highlights key differences in resource allocation, scalability, and cost implications.
| Type | Resources | Scalability | Cost |
|---|---|---|---|
| Virtual Machine (VM) | Virtualized hardware resources (CPU, RAM, storage) shared with other VMs on the same physical server. Resources can be adjusted as needed. | Highly scalable; resources can be easily increased or decreased based on demand. Auto-scaling options are often available. | Generally cost-effective, particularly for variable workloads. Pricing is usually based on consumption (pay-as-you-go). |
| Dedicated Server | Entire physical server dedicated to a single user or application. Provides complete control over hardware resources. | Scalability is limited by the physical hardware. Increasing resources requires provisioning a new server. | Generally more expensive than VMs, especially for smaller applications. Cost is typically fixed, regardless of usage. |
| Cloud Container | Lightweight, isolated environment that packages an application and its dependencies. Shares underlying operating system with other containers. | Highly scalable; containers can be easily deployed and replicated across multiple servers. Orchestration tools manage scaling automatically. | Cost-effective for microservices and containerized applications. Pricing is often based on resource consumption and container runtime. |
Advantages and Disadvantages of Cloud Server Types
Each cloud server type presents unique advantages and disadvantages. Understanding these trade-offs is essential for making the right choice for your specific needs.
Virtual Machines (VMs):
- Advantages: Cost-effective, highly scalable, easy to manage, readily available.
- Disadvantages: Shared resources can lead to performance limitations under high load, less control over hardware compared to dedicated servers.
Dedicated Servers:
- Advantages: Complete control over hardware, predictable performance, enhanced security.
- Disadvantages: High cost, limited scalability, requires more management overhead.
Cloud Containers:
- Advantages: Highly scalable, efficient resource utilization, excellent for microservices architectures, fast deployment.
- Disadvantages: Requires expertise in containerization technologies, potential security concerns if not properly configured.
Cloud Server Selection Process
The flowchart below illustrates a simplified decision-making process for selecting the appropriate cloud server type. It guides you through a series of questions to identify the optimal solution based on your specific requirements.
Imagine a flowchart. It would start with a central question: “What are your application requirements and budget?” This would branch into two paths: “High performance, demanding application, large budget” and “Cost-effective solution, less demanding application, smaller budget.”
The first path (“High performance…”) would lead to a decision node offering “Dedicated Server” as the primary recommendation, with a secondary path considering “Virtual Machines with high resource allocation.”
The second path (“Cost-effective…”) would lead to a decision node: “Is your application containerized?” A “Yes” answer would lead to “Cloud Containers,” while a “No” answer would lead to “Virtual Machines.”
Each decision node would also have considerations for scalability and specific resource needs, influencing the final choice.
Cloud Server Deployment Models
Choosing the right cloud server deployment model is crucial for optimizing performance, security, and cost-effectiveness. The three primary models – public, private, and hybrid – each offer distinct advantages and disadvantages depending on an organization’s specific needs and resources. Understanding these differences is essential for making an informed decision.
This section compares and contrasts public, private, and hybrid cloud server deployments, detailing their security considerations and outlining scenarios where each model is most suitable. We will analyze each model across key factors including security, cost, and level of control.
Comparison of Public, Private, and Hybrid Cloud Deployments
The following table summarizes the key differences between public, private, and hybrid cloud deployment models:
| Deployment Model | Security | Cost | Control |
|---|---|---|---|
| Public Cloud | Shared responsibility model; relies heavily on the provider’s security measures. Vulnerabilities in the shared infrastructure can impact multiple tenants. | Generally lower upfront costs, pay-as-you-go pricing. Costs can escalate unexpectedly with increased usage. | Limited control over infrastructure; managed by the cloud provider. |
| Private Cloud | Higher level of security as resources are dedicated and isolated. Organization retains greater control over security measures. | Higher upfront investment required for infrastructure and maintenance. Ongoing operational costs are also significant. | Complete control over infrastructure and its configuration. |
| Hybrid Cloud | Combines the security aspects of both public and private clouds. Security measures must be carefully coordinated across both environments. | Moderate cost; balances the initial investment of private cloud with the pay-as-you-go flexibility of public cloud. | Partial control; organization retains control over private cloud resources while leveraging the scalability and flexibility of the public cloud. |
Security Considerations for Each Deployment Model
Security is a paramount concern in any cloud deployment. The specific security considerations vary significantly depending on the chosen model.
- Public Cloud:
- Relying on the provider’s security infrastructure and compliance certifications is crucial.
- Data encryption both in transit and at rest is essential.
- Implementing robust access control measures, including multi-factor authentication, is vital.
- Regular security audits and vulnerability assessments are necessary to identify and mitigate potential threats.
- Private Cloud:
- Complete responsibility for security rests with the organization.
- Implementing a comprehensive security information and event management (SIEM) system is critical.
- Regular patching and updates are essential to protect against vulnerabilities.
- Employing a dedicated security team or outsourcing security expertise is often necessary.
- Hybrid Cloud:
- Maintaining consistent security policies and procedures across both public and private environments is paramount.
- Secure data transfer mechanisms between the public and private clouds are crucial.
- Centralized security monitoring and management tools are needed to provide a holistic view of the security posture.
- Robust access control and identity management are vital to control access to resources across both environments.
Suitable Scenarios for Each Deployment Model
The choice of deployment model depends heavily on specific organizational requirements. Each model is best suited for different scenarios.
- Public Cloud: Ideal for startups, small businesses, and organizations with fluctuating workloads. The pay-as-you-go model allows for cost-effective scaling and reduced upfront investment. Examples include a rapidly growing e-commerce business needing scalable web hosting or a small marketing agency needing on-demand compute power for data analysis.
- Private Cloud: Best suited for organizations with stringent security and compliance requirements, such as financial institutions or government agencies. It provides complete control over data and infrastructure, minimizing the risk of data breaches and ensuring compliance with regulations. An example would be a bank needing a highly secure environment for storing and processing sensitive customer data.
- Hybrid Cloud: Provides the best of both worlds, combining the cost-effectiveness and scalability of public cloud with the security and control of private cloud. It’s suitable for organizations with a mix of workloads, some requiring high security and others needing scalability and flexibility. A large enterprise might use a hybrid cloud to run mission-critical applications on their private cloud while leveraging public cloud for less sensitive tasks or during peak demand.
Server Management and Monitoring
Effective server management and monitoring are crucial for ensuring the reliability, performance, and security of your cloud infrastructure. Proactive management minimizes downtime, optimizes resource utilization, and safeguards against potential threats. This section details best practices and essential tasks involved in maintaining a healthy and efficient cloud server environment.
Regular server management involves a combination of preventative measures and responsive actions. Understanding your server’s performance characteristics, identifying potential bottlenecks, and establishing robust monitoring systems are all key elements of a successful strategy. This allows for swift identification and resolution of issues, preventing minor problems from escalating into major outages.
Common Server Management Tasks
Several routine tasks are vital for maintaining a secure and efficient cloud server. These tasks, performed regularly and systematically, significantly reduce the risk of security breaches, performance degradation, and data loss.
- Patching and Updates: Regularly applying operating system and application patches is paramount. These updates often contain critical security fixes and performance improvements. A scheduled patching process, tested in a staging environment before deployment to production, minimizes disruption and maximizes security. Failing to update can leave your server vulnerable to exploits.
- Backups: Implementing a robust backup strategy is crucial for data protection. This involves regularly backing up critical data to a separate location, ideally offsite and using a different cloud region for redundancy. A 3-2-1 backup strategy (3 copies of data, on 2 different media, with 1 offsite copy) is a widely accepted best practice. Regular testing of the backup and restore process is equally important to ensure data recoverability.
- Security Hardening: Securing your server involves configuring firewalls, disabling unnecessary services, and using strong passwords. Regular security audits and penetration testing can identify vulnerabilities and help strengthen your server’s defenses. Implementing multi-factor authentication adds an extra layer of protection against unauthorized access.
- Resource Monitoring: Continuously monitoring CPU utilization, memory usage, disk space, and network traffic helps identify performance bottlenecks and potential issues. This allows for proactive resource allocation and scaling, ensuring optimal server performance.
- Log Management: Regularly reviewing server logs provides valuable insights into system activity, identifying potential problems or security incidents. Centralized log management solutions can simplify the process of analyzing large volumes of log data.
Server Monitoring Tools and Functionalities
A variety of tools are available to monitor cloud servers, each offering different functionalities and levels of sophistication. Choosing the right tool depends on your specific needs and budget. Many offer free tiers or trials, allowing you to evaluate their capabilities before committing to a paid subscription.
- Datadog: Provides comprehensive monitoring of servers, applications, and infrastructure, offering real-time dashboards, alerts, and anomaly detection. It integrates with various cloud platforms and applications.
- Prometheus: An open-source monitoring system that collects metrics from various sources and provides alerts based on predefined rules. It’s highly scalable and customizable, often used in conjunction with Grafana for visualization.
- Nagios: A widely used open-source monitoring system that checks the status of servers, applications, and services, sending alerts when problems occur. It’s known for its flexibility and extensive plugin ecosystem.
- CloudWatch (AWS): A fully managed monitoring and logging service provided by Amazon Web Services. It automatically collects metrics from AWS resources and allows for custom metrics and alarms.
- Azure Monitor (Microsoft Azure): Microsoft’s cloud monitoring service that collects and analyzes data from Azure resources and on-premises servers. It provides dashboards, alerts, and log analytics capabilities.
Cloud Server Security
Securing cloud servers is paramount for maintaining data integrity, ensuring business continuity, and complying with regulations. A robust security strategy must address various threats and vulnerabilities inherent in the cloud environment, encompassing both technical and procedural safeguards. This section details common threats, mitigation strategies, and the crucial role of firewalls, intrusion detection systems, and access control lists.
Common Security Threats and Mitigation Strategies
Cloud servers, while offering numerous advantages, are susceptible to a range of security threats. Effective mitigation requires a proactive and multi-layered approach. The following table Artikels common threats and their corresponding mitigation strategies:
| Threat | Mitigation |
|---|---|
| Data breaches due to unauthorized access | Implement strong authentication mechanisms (multi-factor authentication, password managers), regularly update software and firmware, and enforce least privilege access controls. |
| Malware infections | Utilize robust antivirus and anti-malware solutions, regularly scan systems for vulnerabilities, and maintain up-to-date security patches. Implement sandboxing for untrusted applications. |
| Denial-of-service (DoS) attacks | Implement distributed denial-of-service (DDoS) mitigation services, utilize load balancing to distribute traffic, and configure robust firewalls with rate limiting. |
| Insider threats | Enforce strict access control policies, implement regular security audits and employee training programs focusing on security awareness, and monitor user activity for suspicious behavior. |
| Misconfigurations | Follow security best practices during server setup and configuration. Utilize infrastructure-as-code (IaC) tools for automated and consistent deployments. Implement regular security assessments. |
| Vulnerabilities in third-party applications | Vet third-party applications thoroughly before deployment, regularly update applications, and monitor for security updates and patches from vendors. |
Firewall and Intrusion Detection System Implementation
Firewalls act as the first line of defense, controlling network traffic in and out of the cloud server. In a cloud environment, firewalls can be implemented at multiple layers: network firewalls, host-based firewalls, and web application firewalls. Network firewalls filter traffic based on IP addresses, ports, and protocols. Host-based firewalls protect individual servers. Web application firewalls protect web applications from specific attacks. Intrusion detection systems (IDS) monitor network traffic and server logs for malicious activity, alerting administrators to potential security breaches. Cloud providers often offer managed firewall and IDS services, simplifying deployment and management. Effective implementation requires careful configuration of rules and regular monitoring of logs for suspicious events. For example, a properly configured firewall could block unauthorized access attempts from specific IP addresses known for malicious activity. An IDS might detect and alert on a potential SQL injection attempt against a web application.
Access Control Lists (ACLs) and Configuration
Access control lists (ACLs) are crucial for controlling access to cloud server resources. ACLs define which users or groups have permission to access specific resources and what actions they can perform. Effective ACL configuration follows the principle of least privilege, granting only the necessary permissions to each user or group. ACLs can be implemented at various levels, including network level (controlling network access), storage level (controlling access to storage resources), and application level (controlling access to specific application features). For instance, a database administrator might have full access to a database server, while a regular user only has read-only access. Regular review and updates of ACLs are essential to ensure that permissions remain appropriate and aligned with evolving security needs. Failing to regularly review ACLs can lead to vulnerabilities where users retain access they no longer require, increasing the potential for security breaches.
Cloud Server Cost Optimization

Managing cloud server costs effectively is crucial for maintaining a healthy budget and maximizing the return on investment. Uncontrolled spending can quickly escalate, impacting profitability. This section Artikels strategies to optimize cloud spending and provides a framework for creating a cost-effective cloud server deployment plan.
Cloud computing offers significant flexibility, but this flexibility comes with the potential for unforeseen expenses. Understanding different pricing models and employing proactive cost management techniques are essential to avoid cost overruns. A well-defined cost optimization plan, integrated into the initial deployment strategy, is key to long-term financial health.
Right-Sizing Instances and Reserved Instances
Right-sizing instances involves selecting the appropriate server size (compute, memory, storage) for your application’s needs. Over-provisioning, choosing a larger instance than necessary, leads to wasted resources and increased costs. Under-provisioning, conversely, can result in performance bottlenecks and application instability. Analyzing resource utilization metrics (CPU, memory, network I/O) is crucial to identify instances that can be downsized.
Reserved instances offer significant cost savings by committing to a specific instance type and duration. The discount offered varies depending on the commitment term (one or three years) and the instance type. For applications with predictable resource requirements and long lifecycles, reserved instances represent a substantial cost-reduction strategy. For example, a company running a critical database server 24/7 might see substantial savings by opting for a three-year reserved instance compared to paying on-demand rates.
Cloud Pricing Models
Several pricing models exist within the cloud, each with different implications for cost management. The most common models include:
- On-demand pricing: Pay-as-you-go model, offering flexibility but potentially higher costs for sustained usage.
- Reserved instances: Pre-purchased instances offering significant discounts for long-term commitments.
- Spot instances: Unused compute capacity offered at significantly reduced prices, suitable for fault-tolerant and flexible workloads. However, these instances can be terminated with short notice.
- Savings Plans: Committing to a certain amount of compute usage over a period results in discounts. This offers flexibility compared to reserved instances.
Choosing the right pricing model depends on the application’s characteristics, usage patterns, and risk tolerance. A thorough analysis of resource utilization and future projections is necessary to make an informed decision.
Cost Optimization Plan Example
Let’s consider a hypothetical e-commerce website. Initially, the website is deployed using on-demand instances. After a month of operation, resource utilization monitoring reveals that several instances are consistently underutilized. A cost optimization plan could involve the following steps:
- Right-sizing: Downsize over-provisioned instances to smaller, more cost-effective sizes based on observed resource usage.
- Reserved Instances: For critical database and web servers, transition to reserved instances to benefit from long-term discounts. The commitment period should align with the projected lifespan of the application.
- Spot Instances: Evaluate the feasibility of using spot instances for less critical tasks such as background processing or batch jobs. This leverages unused compute capacity for significant cost reductions.
- Automation: Implement automated scaling to dynamically adjust the number of instances based on real-time demand. This avoids over-provisioning during low-traffic periods.
- Monitoring and Reporting: Regularly monitor cloud spending using the provider’s cost management tools and establish alerts for unexpected cost increases.
By implementing this plan, the e-commerce website can significantly reduce its cloud spending while maintaining application performance and reliability. The specific strategies and their effectiveness will depend on the individual application and its resource consumption patterns.
Serverless Computing

Serverless computing represents a paradigm shift in application development and deployment. Instead of managing servers directly, developers deploy code as individual functions that execute in response to events, without the need for continuous server provisioning or management. This approach offers significant advantages over traditional cloud server models, particularly in terms of scalability, cost efficiency, and operational simplicity.
Serverless computing abstracts away the complexities of server management, allowing developers to focus solely on writing and deploying code. The underlying infrastructure is managed entirely by the cloud provider, ensuring high availability, automatic scaling, and seamless updates. This eliminates the burden of server maintenance, patching, and capacity planning, resulting in faster development cycles and reduced operational overhead.
Serverless Functions versus Virtual Machines
Serverless functions and virtual machines (VMs) represent fundamentally different approaches to cloud computing. VMs provide a dedicated, isolated environment where an entire operating system and applications run continuously. This provides significant control and customization but requires ongoing management and resource allocation. In contrast, serverless functions are ephemeral; they are invoked only when triggered by an event and terminate after execution. This event-driven architecture minimizes resource consumption and costs, making it ideal for microservices and event-driven applications. The key differences lie in resource allocation (continuous vs. on-demand), management overhead (high vs. low), and scaling capabilities (manual vs. automatic). A VM is akin to renting an entire apartment, while a serverless function is like using a shared workspace for a specific task.
Use Cases for Serverless Computing
Serverless computing excels in scenarios characterized by unpredictable workloads, short-lived tasks, and event-driven architectures. Several compelling use cases highlight its benefits:
Examples include:
- Backend APIs: Serverless functions are well-suited for building RESTful APIs and microservices that handle individual requests efficiently. The scalability of the serverless platform ensures that the API can handle fluctuating demand without performance degradation.
- Real-time Data Processing: Serverless functions can process data streams from various sources (e.g., IoT devices, social media feeds) in real-time. Each incoming data point triggers a function execution, enabling immediate analysis and action.
- Image and Video Processing: Tasks such as image resizing, thumbnail generation, and video transcoding can be efficiently handled by serverless functions, automatically scaling to accommodate varying processing loads.
- Mobile Backends: Serverless functions provide a scalable and cost-effective solution for handling mobile application backend operations, such as user authentication, data synchronization, and push notifications.
Cloud Server Scalability and Elasticity
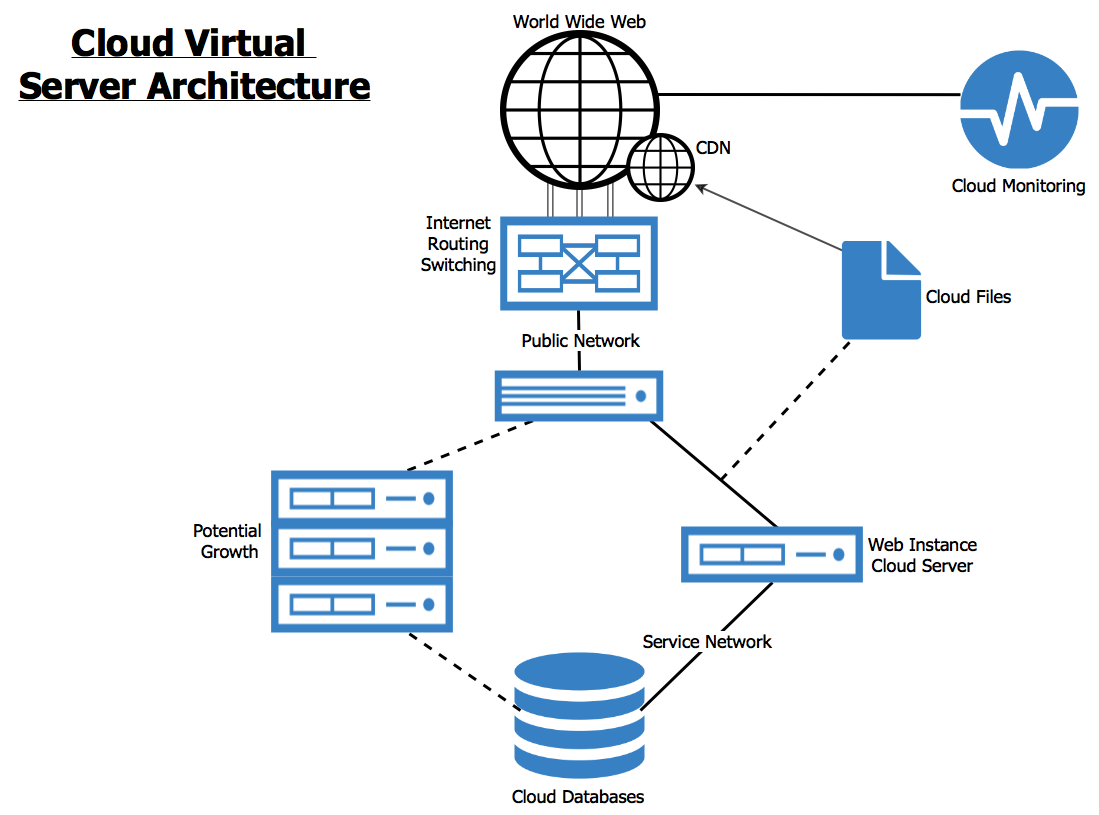
Cloud computing’s power lies in its ability to adapt to fluctuating demands. Scalability and elasticity are key features enabling this adaptability, allowing cloud servers to seamlessly handle varying workloads without significant performance degradation or service interruptions. Understanding and implementing these concepts are crucial for building robust and cost-effective cloud solutions.
Scalability refers to the ability of a system to handle a growing amount of work, whether by increasing the number of users, data volume, or transactions. Elasticity, on the other hand, is the ability of a system to automatically adjust resources in response to real-time demand. While related, they are distinct concepts: scalability is about *potential* growth, while elasticity is about *dynamic* adjustment. A scalable system *can* handle increased load, while an elastic system *automatically does* handle increased load.
Designing a Scalable and Elastic Cloud Server Architecture
Designing for scalability and elasticity requires a proactive approach, starting with the foundational architecture. Key considerations include choosing the right cloud services, implementing appropriate resource provisioning strategies, and employing autoscaling mechanisms. A well-designed architecture should anticipate growth and incorporate mechanisms for easy scaling both vertically (increasing resources on existing servers) and horizontally (adding more servers). This often involves using microservices architecture, where applications are broken down into smaller, independent services that can be scaled independently. For example, a large e-commerce platform might have separate microservices for product catalog, shopping cart, order processing, and payment gateway. Each microservice can be scaled independently based on its specific demands, ensuring efficient resource utilization.
Handling Traffic Spikes and Bursts Using Auto-Scaling Features
Auto-scaling is a crucial component of elastic cloud environments. It allows the system to automatically adjust the number of instances running based on predefined metrics, such as CPU utilization, memory usage, or network traffic. When a traffic spike occurs, auto-scaling triggers the creation of additional instances to handle the increased load. Conversely, when demand decreases, it automatically terminates unnecessary instances, optimizing resource usage and reducing costs. For instance, a website expecting a surge in traffic during a holiday sale can configure auto-scaling to add more server instances in anticipation of the increased demand. Once the sale ends, the extra instances are automatically removed, preventing unnecessary expenses. This is often configured using cloud provider specific tools, which allow setting thresholds for various metrics and defining scaling policies. For example, Amazon Web Services (AWS) offers Auto Scaling, Google Cloud Platform (GCP) offers Cloud Auto Scaling, and Microsoft Azure offers Azure Autoscale. These services provide sophisticated capabilities to manage scaling based on various metrics and conditions.
Data Backup and Disaster Recovery
Data backup and disaster recovery (DR) are critical components of any robust cloud server strategy. Regular backups protect your valuable data from accidental deletion, corruption, or hardware failure, while a comprehensive DR plan ensures business continuity in the event of a major outage or disaster. Implementing effective backup and DR solutions minimizes downtime and data loss, safeguarding your organization’s operations and reputation.
Data backup and disaster recovery strategies for cloud servers differ slightly from on-premises solutions due to the inherent characteristics of the cloud environment. The shared responsibility model, where the cloud provider manages the underlying infrastructure and the user manages their data and applications, necessitates a clear understanding of who is responsible for what in the backup and recovery process. This shared responsibility dictates the choice of backup methods, recovery point objectives (RPOs), and recovery time objectives (RTOs).
Best Practices for Backing Up Data from Cloud Servers
Regular, automated backups are essential. A well-defined backup schedule should consider factors such as data volume, criticality, and regulatory requirements. Employing incremental or differential backups can significantly reduce storage space and backup time compared to full backups. Data should be backed up to multiple locations, ideally geographically dispersed, to protect against regional outages or disasters. This often involves using cloud storage services separate from the primary server location or employing a hybrid approach involving both cloud and on-premises backup solutions. Regular testing of the backup and restore process is crucial to ensure its effectiveness and identify potential issues before a real disaster occurs. Versioning of backups allows for reverting to previous states in case of accidental data modification or corruption. Encryption of backups protects sensitive data during transit and storage.
Disaster Recovery Strategies for Cloud Servers
Several strategies exist for recovering from a disaster affecting cloud servers. These strategies vary in complexity and cost, depending on the organization’s RTO and RPO requirements. A common approach is using a geographically redundant setup, where data and applications are replicated to a secondary region. In the event of a primary region failure, operations can seamlessly switch over to the secondary region with minimal downtime. Another approach is employing a cold standby system, where a backup server is kept in a non-operational state and only activated during a disaster. This is generally less expensive but has a longer RTO. Cloud providers often offer various disaster recovery services, including automated failover mechanisms and managed recovery solutions, which simplify the process and reduce the burden on the organization. The choice of strategy depends on factors such as budget, application criticality, and acceptable downtime.
Disaster Recovery Plan for a Hypothetical Cloud Server Environment
This plan Artikels steps for recovering a hypothetical e-commerce platform hosted on AWS.
- Step 1: Risk Assessment and Business Impact Analysis (BIA): Identify critical systems and applications, determine their recovery time and recovery point objectives (RTOs and RPOs), and assess potential threats (e.g., natural disasters, cyberattacks).
- Step 2: Backup Strategy: Implement daily incremental backups of the database and application servers to Amazon S3, with a weekly full backup. Utilize Amazon Glacier for long-term archive storage.
- Step 3: Disaster Recovery Site: Establish a geographically separate AWS region as a disaster recovery site using AWS’s multi-region capabilities.
- Step 4: Replication Strategy: Utilize AWS’s replication services (e.g., Amazon RDS Multi-AZ deployments, AWS Elastic Beanstalk Blue/Green deployments) to replicate data and applications to the secondary region.
- Step 5: Failover Mechanism: Configure automated failover using AWS services (e.g., Route 53, Elastic Load Balancing) to automatically switch traffic to the secondary region in case of a primary region failure.
- Step 6: Recovery Procedures: Develop detailed recovery procedures outlining steps for restoring data and applications from backups and switching over to the secondary region.
- Step 7: Testing and Training: Conduct regular disaster recovery drills to test the effectiveness of the plan and train personnel on recovery procedures. This includes simulated failures to ensure the plan functions as intended.
- Step 8: Documentation and Communication: Maintain up-to-date documentation of the disaster recovery plan and establish clear communication channels for notifying stakeholders during an incident.
Migration to Cloud Servers
Migrating on-premise servers to a cloud environment offers significant advantages, including increased scalability, reduced infrastructure costs, and enhanced flexibility. However, a well-planned and executed migration strategy is crucial for a smooth transition and to avoid disruptions to business operations. This section details a step-by-step guide, addresses potential challenges, and provides examples of successful migration approaches.
Step-by-Step Guide for On-Premise Server Migration
A methodical approach is vital for successful cloud server migration. Failing to properly plan can lead to downtime, data loss, and budget overruns. The following steps Artikel a comprehensive migration process.
- Assessment and Planning: Begin by thoroughly assessing your current on-premise infrastructure, identifying all servers, applications, and dependencies. This includes analyzing resource utilization, application compatibility with cloud platforms, and data volume. Develop a detailed migration plan outlining timelines, resource allocation, and potential risks.
- Cloud Provider Selection: Choose a cloud provider that aligns with your business needs and technical requirements. Consider factors such as pricing models, geographic location, security features, and compliance certifications. Evaluate offerings from major providers like AWS, Azure, and Google Cloud Platform.
- Environment Setup: Create the necessary cloud environment, including virtual networks, storage, and security groups. Configure the cloud infrastructure to mirror your on-premise environment as closely as possible to minimize disruptions.
- Data Migration: Migrate your data to the cloud using appropriate methods such as direct transfer, cloud-based replication tools, or third-party migration services. Consider data volume, security requirements, and downtime tolerance when selecting a data migration strategy.
- Application Migration: Migrate your applications to the cloud, either by rehosting (running existing applications on virtual machines), replatforming (refactoring applications to leverage cloud-native services), or refactoring (significantly modifying applications for optimal cloud performance). Choose the approach that best suits your application’s architecture and business needs.
- Testing and Validation: Thoroughly test the migrated applications and data in the cloud environment to ensure functionality, performance, and security. Conduct performance testing to identify and address any bottlenecks.
- Cutover and Go-Live: Once testing is complete, perform a cutover to switch from the on-premise environment to the cloud. This may involve a phased approach, gradually migrating workloads to minimize disruption.
- Post-Migration Monitoring and Optimization: Continuously monitor the performance and security of your cloud environment. Optimize resource utilization and costs based on usage patterns. Regularly review and update your migration strategy as needed.
Challenges and Considerations in Cloud Server Migration
Several challenges can arise during cloud server migration. Careful planning and mitigation strategies are essential to address these potential obstacles.
One major challenge is application compatibility. Some applications may not be compatible with cloud environments without significant modifications. Another challenge is data migration complexity, especially for large datasets. Security concerns are also paramount, requiring careful configuration of security groups, access control lists, and encryption mechanisms. Finally, cost optimization requires careful monitoring and management of cloud resources to avoid unexpected expenses. Understanding these challenges and proactively addressing them is critical for a successful migration.
Examples of Successful Cloud Server Migration Strategies
Many organizations have successfully migrated their on-premise servers to the cloud. For example, a large retail company migrated its e-commerce platform to AWS, achieving significant scalability improvements during peak shopping seasons. They leveraged AWS’s auto-scaling capabilities to handle fluctuating traffic demands effectively. Another example is a financial institution that migrated its core banking system to Azure, enhancing security and compliance with industry regulations. This involved a phased migration approach to minimize disruption to banking operations. These successful migrations demonstrate the benefits of careful planning, thorough testing, and a phased approach.
Key Questions Answered
What is the difference between IaaS and PaaS?
IaaS (Infrastructure as a Service) provides virtualized computing resources like servers, storage, and networking. PaaS (Platform as a Service) offers a complete platform for developing and deploying applications, including pre-configured environments and tools.
How do I choose the right cloud provider?
Consider factors like cost, scalability, security features, geographic location, compliance certifications, and the provider’s reputation and customer support when selecting a cloud provider.
What are the security implications of using a public cloud?
Public clouds share resources, requiring careful attention to data encryption, access control, and regular security audits to mitigate risks. Shared responsibility models dictate that both the provider and the user share security responsibilities.
How can I monitor my cloud server performance?
Utilize cloud provider monitoring tools or third-party solutions to track CPU usage, memory consumption, network traffic, and other key metrics. Establish baselines and set alerts to identify potential issues promptly.